Vision
The project starts from a simple fragility claim: static rules and local
behavior specifications are necessary, but not sufficient, for chatbot systems
that run for months or years. Users change, models are swapped, memories are
compressed, tools return bad information, and a rule written at deployment time
cannot anticipate every destabilizing trajectory.
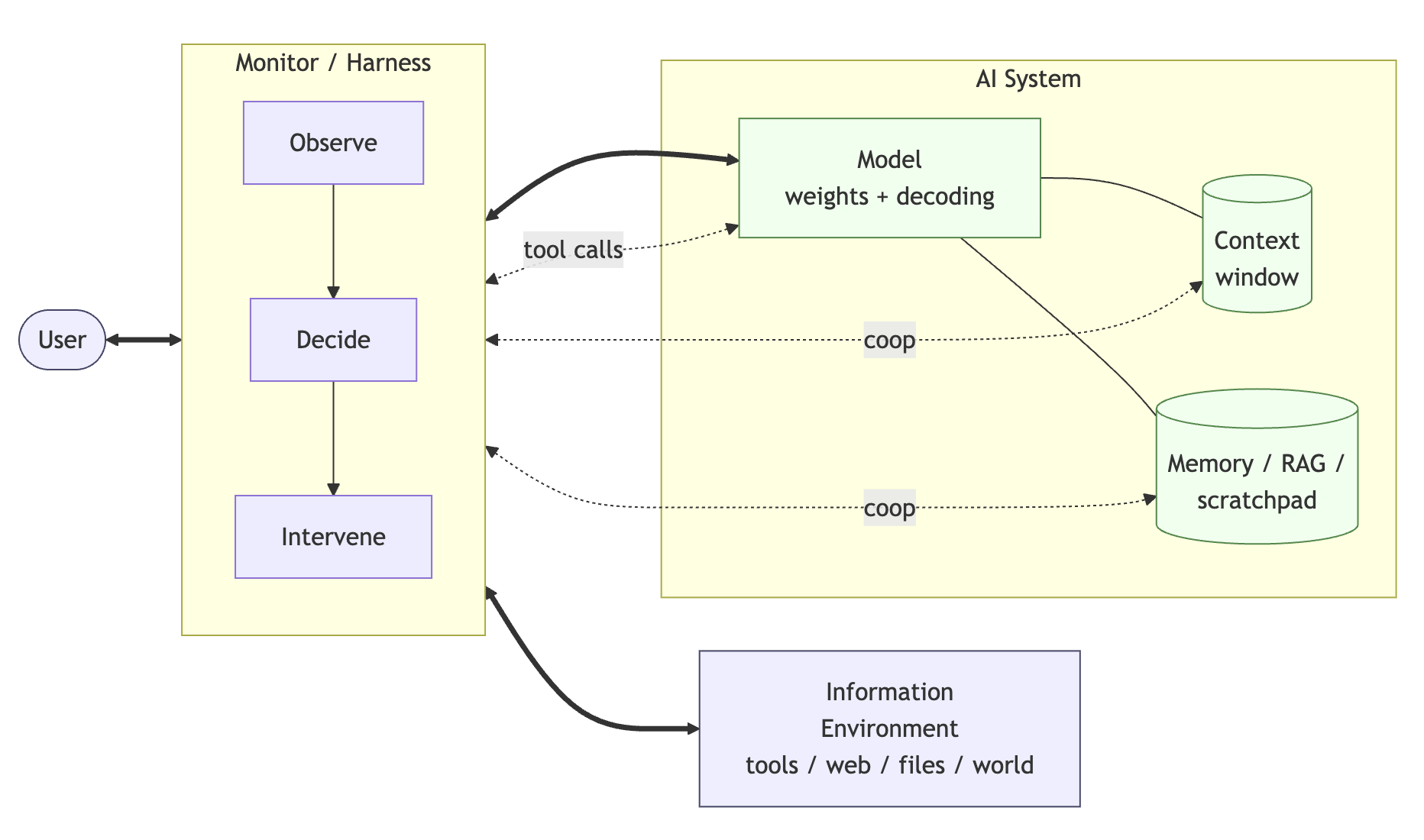
A resilience harness reframes the safety object from a box around a model to a
stateful structure around an ongoing relationship. It observes the user, the AI
system, and the operating environment as separate health channels, preserves
their disagreement, and turns drift into something measurable rather than a
vague after-the-fact failure.
The core architecture therefore separates perception, memory, forward models,
valuation, and repair. The chatbot remains the conversational self, but the
harness carries a second viewpoint: one that can remember commitments, forecast
how candidate responses may move channel state, and prepare interventions such
as clarification, slowdown, refusal, recovery, or handoff.
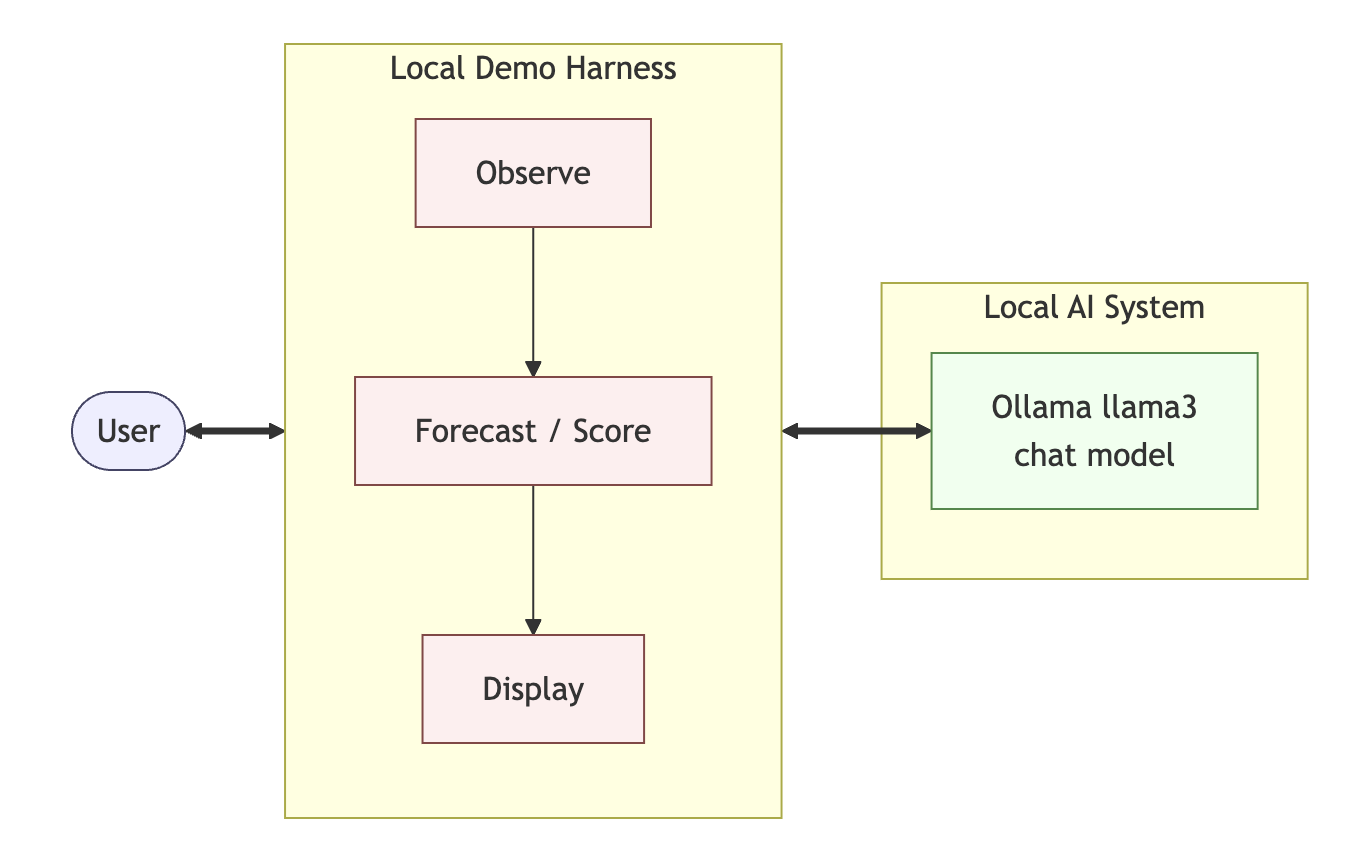
The near-term engineering target is modest and concrete. Build auditable,
swappable harness components that make a harnessed chatbot measurably more
resilient than a bare chatbot under long-running, changing, and sometimes
destabilizing conditions.